Data streaming
Streaming data is data that is continuously generated by different sources. Such data should be processed incrementally using Stream Processing techniques without having access to all of the data. In addition, it should be considered that concept drift may happen in the data which means that the properties of the stream may change over time. It is usually used in the context of big data in which it is generated by many different sources at high speed. Data streaming can also be explained as a technology used to deliver content to devices over the internet, and it allows users to access the content immediately, rather than having to wait for it to be downloaded.

Difficulty in data streaming
Mainly we can see two problems when talking about data streaming.
· How to get data from many different sources flowing into your cluster
· How to process it when it is there
· How to deliver to the subscribers
· Wow to manage these functionalities by producer
Kafka gives the solution

- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
What is actually this Kafka
It is a general-purpose publish/subscribe messaging system. Kafka servers store all incoming messages from publishers for some period of time and publish them to a stream of data called a topic. Kafka consumer subscribe to one or more topics and receive data as it's published. A stream/topic can have many different consumers, all with their own position in the stream maintained.
How Kafka scales
Kafka, itself may be distributed among many processes on may servers.
- Will distribute the storage of stream data as well
- If it faces any failure it has multiple servers to produce multiple processors
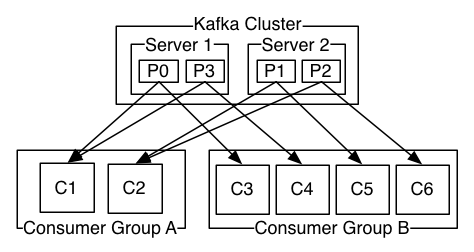
(In below example, Server1 and server 2 consist with )
Consumers may also be distributed
- A consumer of the same group will have massages distributed among them.
- A consumer of a different group will get their own copy of each message.
(In below example, Consumer Group A can cover server 1 and server 2 both by C1 and C2)
Set up Kafka locally
I am going to explain how to install Kafka on Ubuntu. To install Kafka, Java must be installed on your system. It is a must to set up ZooKeeper for Kafka. ZooKeeper performs many tasks for Kafka but in short, we can say that ZooKeeper manages the Kafka cluster state.
ZooKeeper Setup
Kafka Setup
- Download ZooKeeper from "https://www.apache.org/dyn/closer.cgi/zookeeper/".
- Unzip the file. Inside the conf directory, rename the file zoo_sample.cfgas zoo.cfg.
- The zoo.cfg file keeps configuration for ZooKeeper, i.e. on which port the ZooKeeper instance will listen, data directory, etc.
- The default listen port is 2181. You can change this port by changing clientPort.
- The default data directory is /tmp/data. Change this, as you will not want ZooKeeper's data to be deleted after some random timeframe. Create a folder with the name data in the ZooKeeper directory and change the dataDir in zoo.cfg.
- Go to the bin directory.
- Start ZooKeeper by executing the command ./zkServer.sh start.
- Stop ZooKeeper by stopping the command ./zkServer.sh stop.
- Download the latest stable version of Kafka from "https://kafka.apache.org/downloads".
- Unzip this file. The Kafka instance (Broker) configurations are kept in the config directory.
- Go to the config directory. Open the file server.properties.
- Remove the comment from listeners property, i.e. listeners=PLAINTEXT://:9092. The Kafka broker will listen on port 9092.
- Change log.dirs to /kafka_home_directory/kafka-logs.
- Check the zookeeper. connect property and change it as per your needs. The Kafka broker will connect to this ZooKeeper instance.
- Go to the Kafka home directory and execute the command ./bin/kafka-server-start.sh config/server.properties.
- Stop the Kafka broker through the command ./bin/kafka-server-stop.sh.
Kafka Brocker Properties
For beginners, the default configurations of the Kafka broker are good enough, but for production-level setup, one must understand each configuration. I am going to explain some of these configurations.
- broker.id: The ID of the broker instance in a cluster.
- zookeeper.connect: The ZooKeeper address (can list multiple addresses comma-separated for the ZooKeeper cluster). Example: localhost:2181,localhost:2182.
- zookeeper.connection.timeout.ms: Time to wait before going down if, for some reason, the broker is not able to connect.
Socket Server Properties
- socket.send.buffer.bytes: The send buffer used by the socket server.
- socket.receive.buffer.bytes: The socket server receives a buffer for network requests.
- socket.request.max.bytes: The maximum request size the server will allow. This prevents the server from running out of memory.
Flush Properties
Each arriving message at the Kafka broker is written into a segment file. The catch here is that this data is not written to the disk directly. It is buffered first. The below two properties define when data will be flushed to disk. Very large flush intervals may lead to latency spikes when the flush happens and a very small flush interval may lead to excessive seeks.
- log.flush.interval.messages: Threshold for message count that is once reached all messages is flushed to the disk.
- log.flush.interval.ms: Periodic time interval after which all messages will be flushed into the disk.
Log Retention
As discussed above, messages are written into a segment file. The following policies define when these files will be removed.
- log.retention.hours: The minimum age of the segment file to be eligible for deletion due to age.
- log.retention.bytes: A size-based retention policy for logs. Segments are pruned from the log unless the remaining segments drop below log.retention.bytes.
- log.segment.bytes: Size of the segment after which a new segment will be created.
- log.retention.check.interval.ms: Periodic time interval after which log segments are checked for deletion as per the retention policy. If both retention policies are set, then segments are deleted when either criterion is met.
Comments
Post a Comment