
What is Kubernetes
- Kubernetes is an open source system for automating deployment, scaling, and management of containerized applications.
- Kubernetes, at its basic level, is a system for running and coordinating containerized applications across a cluster of machines. It is a platform designed to completely manage the life cycle of containerized applications and services using methods that provide predictability, scalability, and high availability.
- As a Kubernetes user, you can define how your applications should run and the ways they should be able to interact with other applications or the outside world.
Kubernetes Features
- Service discovery and load balancing:
- Storage orchestration:
- Automated rollouts and rollbacks:
- Batch execution:
- Automatic bin packing:
- Self-healing:
- Secret and configuration management:
- Horizontal scaling:
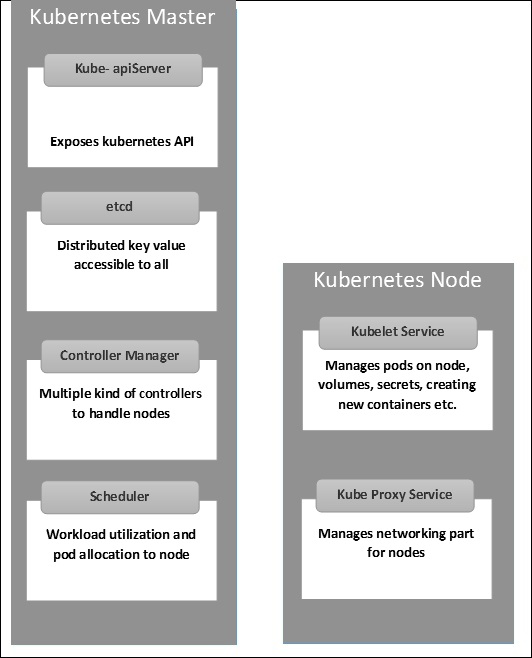
Kubernetes Architecture

Kubernetes Master Component
- API service: Kubernetes is an API server which provides all the operation on the cluster using the API. API server implements an interface, which means different tools and libraries can readily communicate with it.
- Scheduler: responsible for distributing the workload and allocating pod to the new node.
- Controller-manager: It is a nonterminating loop and is responsible for collecting and sending information to the API server.
- etcd: stores the configuration information as key-value pairs which can be used by each of the nodes in the cluster.
Kubernetes Node Component
- Docker: helps in running the encapsulated application containers in a relatively isolated but lightweight operating environment.
- Kubelet service: This communicates with the master component (etcd) to receive commands and work.
- Kubernetes Proxy Service: Helps in forwarding the request to correct containers and is capable of performing primitive load balancing.
Implementing a Google Kubernetes Engine cluster on Google Cloud Platform
Introduction to implementation
we are going to set up two services as
- API Service;
This service exposes two API endpoints as "code to state" and "state to code". It is about states in the U.S. and each state has state code. If we search by code it gives the state name as well as using another endpoint, if we search by state name, it gives the state code.
- Data Service;
Prerequisites
- A Google cloud platform account with Kubernetes enabled (https://console.cloud.google.com).
- Docker is required on all the instances of Kubernetes. Docker installed in the local computer (https://docs.docker.com/docker-for-windows/install/).
I used nodeJS applications as services and windows 10 pc for this implementation.
Process
- First of all, we need to login to the Google cloud platform to create a new project. You can create a new project by clicking the top-left corner which shows the project details. After that, you can view the details of your project such as Project ID, Project Name, Project Number, etc. This information is very useful to try to remember that.

- After that try to open the cloud shell from your project window. It’s in the top right corner. After opening up the console write the following commands configure your cluster:
gcloud config set project [PROJECT_ID]
gcloud config set compute/zone [COMPUTEZONE]
gcloud config set compute/region [COMPUTEREGIEON]
(Use this link to get the required zones region: https://cloud.google.com/compute/docs/regions-zones/#available)
Now execute following command to create Kubernetes clusters:
gcloud container clusters create [CLUSTERNAME]
Then login to the cluster:
gcloud container clusters get-credentials [CLUSTERNAME]
Congratulations you have now created standard three machine cluster!
Now the next step. In this step, you have to implement a “Data Service” which can parse API endpoints and grab required data from it to provide a correct response.
To implement the functionality, I will use Nodejs. You can use any kind of scripting language to implement the functionality of data service.
First, implement the logic which I mentioned in “Introduction to API” section. I have implemented it and saved it as “app.js”. After that create “package.json” file that describes your app and its dependencies. Then run:
npm install package.json
This will generate your “package-lock.JSON” file.
Now we have to create a “DockerFile” which is used to create an image of our app so we could push our app to google cloud platform’s Kubernetes cluster.
- To create a DockerFile run this command on the console.
touch Dockerfile
After that, you have to edit the DockerFile by providing required information about your application (Remember to include package.json file). For more information visit this URL: https://docs.docker.com/compose/gettingstarted/. This file is used in Docker when we are building the app, therefore, this will help you to run your app in the server.
Once you created “DockerFile” you have to create. dockerignore file then writes the following lines of code:
node_modules
npm-debug.logThis will prevent your local modules and debug logs from being copied onto your Docker image and possibly overwriting modules installed within your image.
Next step is to build your app your application.
- To build the container image of this application and tag it for uploading, run the following command:
docker build -t gcr.io/${PROJECT_ID}/[Application Name]:[TAG]After that you can view the generated image using the following command:
docker images
Now we need to push our app to the Google cloud platform. Before doing that, it is required to grant access to docker which allows it to push the app.
gcloud auth configure-docker
After finishing those steps now, we can successfully push the app to the cloud platform. But it’s a wise thing to test your app before running in the cloud platform. Use the following command to test your app locally.
gcr.io/{PROJECT_ID}/[ Application Name]:[TAG]If it runs successfully then you can push it into cloud platform using the following command:
docker push gcr.io/{PROJECT_ID}/[ Application Name]:[TAG]
gcloud container images list-tags gcr.io/[PROJECTID]/[APPLICATION NAME]
All the setting up is over. Now you can deploy your app! to deploy and manage applications on a GKE cluster, you must communicate with the Kubernetes cluster management system. You typically do this by using the kubectl command-line tool.
kubectl run [API_ENDPOINT_NAME] — image=gcr.io/{PROJECT_ID}/[ APPLICATION_NAME]:[TAG] — port [port]
Now it’s all working but you can only access your API endpoints locally. To expose your application to the Internet. By default, the containers you run on GKE are not accessible from the Internet, because they do not have external IP addresses. You must explicitly expose your application to traffic from the Internet, run the following command:
kubectl expose deployment [API_ENDPOINT_NAME] — type=LoadBalancer — port [port] — target-port [port]
The kubectl expose command above creates a Service resource, which provides networking and IP support to your application’s Pods.
Now you are all done! You can view your application’s external IP that GKE provisioned for your application by executing the following command:
kubectl get serviceNow you can go to the IP address to provide and test your application’s functionality.
http://[IP address]/codeToState?code=[STATECODE]As for the other API, endpoint follows the same steps as the first one did and you will able to see the expected results as well.
http://35.200.219.217/statetocode?state=[STATENAME]
You Completed It. Congratulations!
Comments
Post a Comment